Tap Encoding Decoding (TED) is a performance art program that decodes language from live tap dancing. The dancer performs steps that percussively encode dots or dashes, as determined by the programmatic constraints of TED. TED listens to the audio and uses signal processing techniques to decode the performed text, leading to a performance partnership between the dancer and TED. During this process we analyzed the nature of collaborating with technology as one's partner for live performance, which can be read about in our paper Virtually Constrained Dancing: Encoding Language in Movement and Sound.
TED began as a personal project, with an early iteration documented here. Professor Lucas Bang assisted in securing student research funding from Harvey Mudd College for me and Shannon Steele to further develop the concept. I was the expert tap dancer, worked on technical development, and provided conceptual direction. TED was developed over 10 weeks during the summer of 2019.
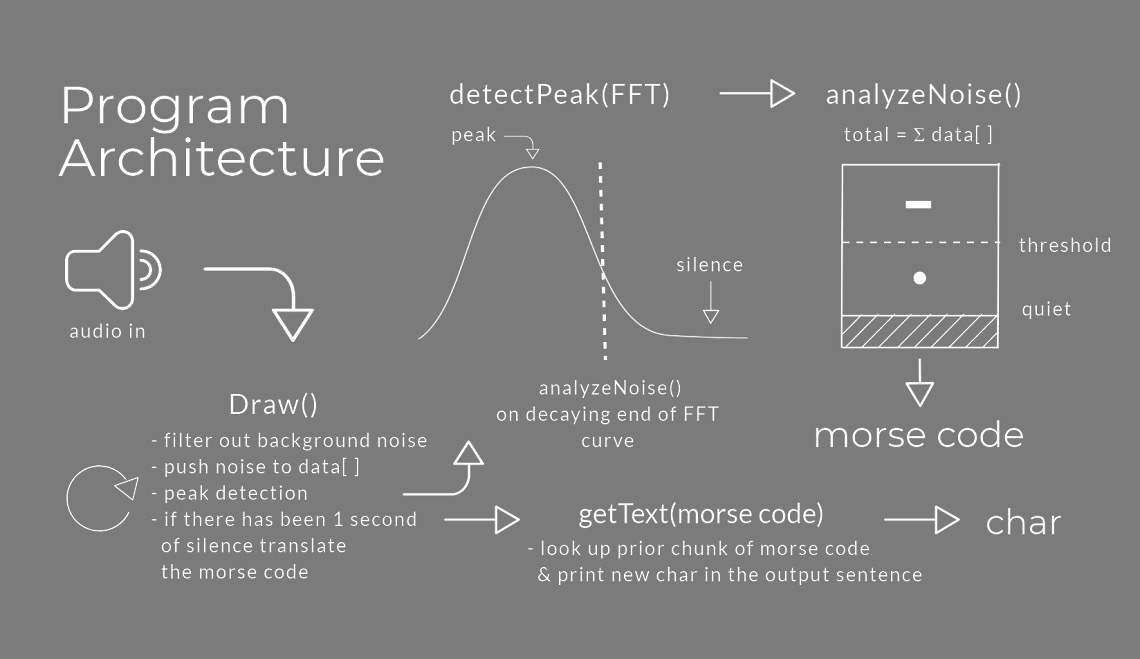
TED listens to accumulated audio and silences to decode dots and dashes. A dash can be produced from a lot of sequential noise or loud noise. A dot will be produced with less sequential noise or quieter noise. When you are done with a dot or a dash leave a small amount of silence before producing the next dot/dash. Longer silences will trigger TED to translate the prior chunk of Morse Code into an English character. The timing and amount of noise needed to produce dots and dashes is best figured out by playing with the program! You can also adjust how much noise is needed for both characters by changing the thresholds.